13 Relational data
13.1 Introduction
데이터 분석을 하는데 있어, 단 하나의 table을 쓰는 경우는 거의 없다.
보통 여러 개의 테이블들이 있고, 니가 궁금한 것에 대해 대답을 하기 위해선, 이것들을 잘 결합combine해야됨.
종합해서, 이 multiple tables of data를 relational data라고 부른다.
단순히 개별적인 데이터셋들이 아니라, relations가 중요하기 때문이다.
Relations라는건, 항상 2개의 테이블에서 정의되는거다.
모든 relations들은 이 간단한 아이디어에서 만들어진 것.
3개 이상의 테이블에서의 relations라는건 항상 2개씩의 relations의 특성.
the relations of three or more tables / are always a property of the relations between each pair.
확장의 개념으로 생각하자.
Relational data에 대해 다루기 위해서는, pairs of tables에 사용되는 verbs를 알아야됨.
3가지의 families of verbs가 있음.
- Mutating joins: 하나의 데이터 프레임에 새로운 변수들을 추가하는 것.
어떤 새로운 변수? 다른 데이터 프레임에서, 매칭이 되는 관측치에 대한 변수
which add new variables to one data frame / from matching observations in another. - Filtering joins: 하나의 데이터 프레임에서 관측치를 필터링 하는 것임.
어떤 기준으로? 다른 데이터 프레임에, 그 관측치에 대한 정보가 있냐없냐에 따라 - Set Operations: 관측치를 set elements인 것처럼 다루는 것.
which treat observations as if they were set elements.
Relational data를 찾을 수 있는 가장 흔한 장소는 relational database management system(RDBMS)이다.
거의 모든 현대 데이터베이스들을 관통하는 단어.
만약에 데이터베이스를 다루어본 적이 있다면, 아마 분명히 SQL을 썼을 것이다.
그렇다면, 이 chapter에서 비슷한 개념을 찾을 수 있을 것이다. 물론 표현은 dplyr에선 조금 다르겠지만.
일반적으로, dplyr은 SQL보다 좀 더 사용하기 쉽다. 왜냐하면 데이터 분석에 특화되어있기 때문에.
일반적인 데이터 분석 작업을 쉽게 만들어 주는데, 데이터 분석에 잘 이용되지 않는 다른 것들은 하기가 좀 힘들어지긴 한다.
it makes common data analysis operations easier, at the expense of making it more difficult to do other things to do other things that aren't commonly needed for data analysis.
13.1.1 Prerequisites
dplyr에서 two-table verbs를 사용함으로써, nycflights13의 relational data를 다루어보자.
library(tidyverse)
library(nycflights13)
13.2 nycflights13
relational data를 배우기 위해서 nycflights13 패키지를 사용할 것이다.
이 패키지는 4개의 tibbles를 갖고 있다.
이 tibble들은, data transformation을 할 때 썼던, flights라는 테이블과 연관이 있는 tibble들.
airlines: 항공사 이름을 단축된 코드로 볼 수 있도록 해준다.
airlines
## # A tibble: 16 x 2
## carrier name
## <chr> <chr>
## 1 9E Endeavor Air Inc.
## 2 AA American Airlines Inc.
## 3 AS Alaska Airlines Inc.
## 4 B6 JetBlue Airways
## 5 DL Delta Air Lines Inc.
## 6 EV ExpressJet Airlines Inc.
## 7 F9 Frontier Airlines Inc.
## 8 FL AirTran Airways Corporation
## 9 HA Hawaiian Airlines Inc.
## 10 MQ Envoy Air
## 11 OO SkyWest Airlines Inc.
## 12 UA United Air Lines Inc.
## 13 US US Airways Inc.
## 14 VX Virgin America
## 15 WN Southwest Airlines Co.
## 16 YV Mesa Airlines Inc.
airports: 각 공항에 대한 정보를 준다. faa라는 airport code로 identify가능.
airports
## # A tibble: 1,458 x 8
## faa name lat lon alt tz dst tzone
## <chr> <chr> <dbl> <dbl> <int> <dbl> <chr> <chr>
## 1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/New_~
## 2 06A Moton Field Municipa~ 32.5 -85.7 264 -6 A America/Chic~
## 3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/Chic~
## 4 06N Randall Airport 41.4 -74.4 523 -5 A America/New_~
## 5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/New_~
## 6 0A9 Elizabethton Municip~ 36.4 -82.2 1593 -5 A America/New_~
## 7 0G6 Williams County Airp~ 41.5 -84.5 730 -5 A America/New_~
## 8 0G7 Finger Lakes Regiona~ 42.9 -76.8 492 -5 A America/New_~
## 9 0P2 Shoestring Aviation ~ 39.8 -76.6 1000 -5 U America/New_~
## 10 0S9 Jefferson County Intl 48.1 -123. 108 -8 A America/Los_~
## # ... with 1,448 more rows
planes: 각 비행기 정보를 준다. tailnum로 identify가능.
planes
## # A tibble: 3,322 x 9
## tailnum year type manufacturer model engines seats speed engine
## <chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
## 1 N10156 2004 Fixed win~ EMBRAER EMB-1~ 2 55 NA Turbo~
## 2 N102UW 1998 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## 3 N103US 1999 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## 4 N104UW 1999 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## 5 N10575 2002 Fixed win~ EMBRAER EMB-1~ 2 55 NA Turbo~
## 6 N105UW 1999 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## 7 N107US 1999 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## 8 N108UW 1999 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## 9 N109UW 1999 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## 10 N110UW 1999 Fixed win~ AIRBUS INDUS~ A320-~ 2 182 NA Turbo~
## # ... with 3,312 more rows
weather: NYC 공항에서의 시간별 날씨를 준다.
weather
## # A tibble: 26,115 x 15
## origin year month day hour temp dewp humid wind_dir wind_speed
## <chr> <dbl> <dbl> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
## 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
## 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
## 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
## 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
## 6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
## 7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
## 8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
## 9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
## 10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
## # ... with 26,105 more rows, and 5 more variables: wind_gust <dbl>,
## # precip <dbl>, pressure <dbl>, visib <dbl>, time_hour <dttm>
다이어그램으로 이 테이블들 간의 관계를 표시해봤다. 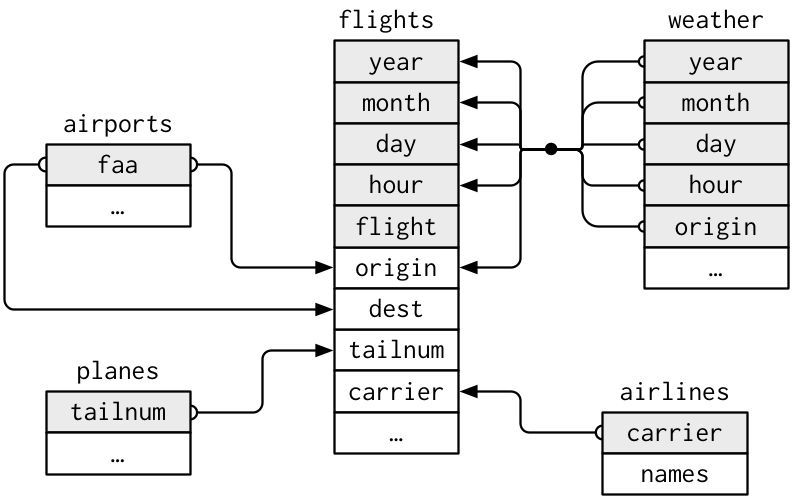
다이어그램은 좀 복잡하긴한데, 필드에 나가서 보게 될 것에 비하면 간단한 편이다(...)
이러한 다이어그램을 이해하는 것의 key는, 각 relation은 한 쌍의 테이블만을 고려한다는 걸 기억하는 것.
The key to understanding diagrams like this / is to remember / each relation always concerns a pair of tables.
다 이해할 필요 없이, 테이블 간의 (니가 관심있는)chain of relations만 이해해라.
이 nycflights13에 관해선,
flights는 planes와 하나의 변수인, tailnum을 통해 연결된다.
flights는 airlines와, carrier 변수를 통해 연결된다.
flights는 airports와 두 가지 방법, origin과 dest 변수들을 통해 연결된다.
flights는 weather와, origin(출발지)와 year와 month와 day 그리고 hour를 통해 연결된다.
13.3 Keys
2개의 tables를 연결시켜주는 변수들을, keys라고 부른다.
keys는 관측치를 unique하게 identify해주는 변수(혹은 변수들).
간단한 케이스에서는, 하나의 변수가 관측치를 identify하기에 충분하다.
예를 들어, planes에서, 각 비행기는 tailnum으로 unique하게 identify된다.
다른 케이스에서는, 여러 개의 변수들이 필요할 수 있다.
예를 들어, weather 자료에서, 관측치를 unique하게 identify하기 위해선, 다섯 개의 변수들이 필요하다. year, month, day, hour 그리고 origin.
2가지 타입의 key가 있다.
-
primary key는 자기 자신의 테이블에서 관측치를 unique하게 identify해주는 것.
예를 들어,planes테이블에서,tailnum은 각 plane을 unique하게 identify해주니깐 primary key다. -
foreign key는 다른 테이블의 관측치를 unique하게 identify해주는 것.
예를 들어,flights에서tailnum은,planes에서 관측치를 unique하게 identify해주니깐 foreign key다.
하나의 변수는, primary key와 foreign key 둘 다 될 수 있다.
예를 들어, origin은 weather 테이블의 primary key 중 일부지만, airport 테이블의 foreign key이기도 하다.
너의 테이블에서, primary keys를 identify하고 났으면, 진짜로 unique하게 각 관측치를 identify하는지 확인해보는건 좋은 습관이다.
하나의 방법은 primary key별로 count()를 해서, n 이 1보다 큰지를 확인해보는 것.
planes %>%
count(tailnum) %>%
filter(n > 1)
## # A tibble: 0 x 2
## # ... with 2 variables: tailnum <chr>, n <int>
weather %>%
count(year, month, day, hour, origin) %>%
filter(n > 1)
## # A tibble: 3 x 6
## year month day hour origin n
## <dbl> <dbl> <int> <int> <chr> <int>
## 1 2013 11 3 1 EWR 2
## 2 2013 11 3 1 JFK 2
## 3 2013 11 3 1 LGA 2
가끔, 명백한 primary key가 없는 테이블이 있을 수도 있다.
그 어떠한 변수 조합들도 관측치 하나만을 identify해주지 못하는 것임.
예를 들어, flights 테이블에서 primary key는 무엇일까?
특정한 날짜에다가 flight 혹은 tailnum를 추가하면 unique하게 identify해주지 않을까? 하지만 확인해보면 아니다.
flights %>%
count(year, month, day, flight) %>%
filter(n > 1)
## # A tibble: 29,768 x 5
## year month day flight n
## <int> <int> <int> <int> <int>
## 1 2013 1 1 1 2
## 2 2013 1 1 3 2
## 3 2013 1 1 4 2
## 4 2013 1 1 11 3
## 5 2013 1 1 15 2
## 6 2013 1 1 21 2
## 7 2013 1 1 27 4
## 8 2013 1 1 31 2
## 9 2013 1 1 32 2
## 10 2013 1 1 35 2
## # ... with 29,758 more rows
flights %>%
count(year, month, day, tailnum) %>%
filter(n > 1)
## # A tibble: 64,928 x 5
## year month day tailnum n
## <int> <int> <int> <chr> <int>
## 1 2013 1 1 N0EGMQ 2
## 2 2013 1 1 N11189 2
## 3 2013 1 1 N11536 2
## 4 2013 1 1 N11544 3
## 5 2013 1 1 N11551 2
## 6 2013 1 1 N12540 2
## 7 2013 1 1 N12567 2
## 8 2013 1 1 N13123 2
## 9 2013 1 1 N13538 3
## 10 2013 1 1 N13566 3
## # ... with 64,918 more rows
맨 처음 이 데이터를 다룰 때, 각 flight number는 하루에 한 번만 쓰일 거라고 순진하게 생각했다.
그럼 이제 특정한 비행specific flight에 대해 소통하기가 쉬웠을텐데, 불운하게도 안 그랬다.
이렇게, 테이블에 primary key가 없으면, mutate()나 row_number()을 통해서 하나 만들어주는게 유용하다.
이러고나면 어떤 필터링을 하고 난 후, original data로 다시 한번 체크할 때, 관측치를 매치하기 쉽게 해준다.
이런 key를 surrogate key라고 부른다.
primary key랑, 다른 테이블에서 상응하는 foreign key는 relation을 형성한다.
A primary key and the corresponding foreign key in another table form a relation.
Relations이란건 기본적으로 일대다one-to-many다.
예를 들어, 각 비행flight은 하나의 비행기를 가지고 있는데, 각 비행기는 여러 개의 비행flight을 가지고 있다.
다른 데이터에선 가끔씩 일대일one-to-one 관계를 볼 수 있다.
이건 일대다one-to-many의 특별한 케이스라고 볼 수 있다.
다대다many-to-many 관계를, 다대일many-to-one에다 일대다one-to-many를 합쳐서 만들수도 있다.
예를 들어, airlines와 airports간의 다대다many-to-many 관계를 볼 수 있다.
각 airline은 여러 개의 airports로 비행을 하고, 각 airport는 여러 개의 airlines를 호스트host하고.
13.3.1 Exercises
13.4 Mutating joins
한 쌍의 테이블을 결합combining할 첫 번째 도구는 mutating join.
mutating join은 두 개의 테이블들에서 변수를 결합할 수 있도록 도와준다.
먼저 keys를 통해서 관측치observation들을 매치하고, 하나의 테이블에서 다른 테이블로 변수를 통해 복사를 하는 것이다.
말로 하는게 더 어렵다. 예를 보면 간단하다.
flights데이터에 칼럼이 너무 많기 때문에, 몇 개의 칼럼만 따로 뽑은 flights2를 쓰겠다.
flights2 <- flights %>%
select(year:day, hour, origin, dest, tailnum, carrier)
flights2
## # A tibble: 336,776 x 8
## year month day hour origin dest tailnum carrier
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr>
## 1 2013 1 1 5 EWR IAH N14228 UA
## 2 2013 1 1 5 LGA IAH N24211 UA
## 3 2013 1 1 5 JFK MIA N619AA AA
## 4 2013 1 1 5 JFK BQN N804JB B6
## 5 2013 1 1 6 LGA ATL N668DN DL
## 6 2013 1 1 5 EWR ORD N39463 UA
## 7 2013 1 1 6 EWR FLL N516JB B6
## 8 2013 1 1 6 LGA IAD N829AS EV
## 9 2013 1 1 6 JFK MCO N593JB B6
## 10 2013 1 1 6 LGA ORD N3ALAA AA
## # ... with 336,766 more rows
이 flights2의 데이터에다가, 항공사 풀네임이라는 새로운 칼럼을 추가하고 싶다고 치자.
left_join()을 이용해서 airlines와 flights2를 결합할 수 있다.
flights2 %>%
select(-origin, -dest) %>%
left_join(airlines, by = "carrier")
## # A tibble: 336,776 x 7
## year month day hour tailnum carrier name
## <int> <int> <int> <dbl> <chr> <chr> <chr>
## 1 2013 1 1 5 N14228 UA United Air Lines Inc.
## 2 2013 1 1 5 N24211 UA United Air Lines Inc.
## 3 2013 1 1 5 N619AA AA American Airlines Inc.
## 4 2013 1 1 5 N804JB B6 JetBlue Airways
## 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
## 6 2013 1 1 5 N39463 UA United Air Lines Inc.
## 7 2013 1 1 6 N516JB B6 JetBlue Airways
## 8 2013 1 1 6 N829AS EV ExpressJet Airlines Inc.
## 9 2013 1 1 6 N593JB B6 JetBlue Airways
## 10 2013 1 1 6 N3ALAA AA American Airlines Inc.
## # ... with 336,766 more rows
airlines랑 겹치는 key인 carrier로 결합한걸 볼 수 있음.
name이라는 변수가 flights2에 추가된 걸 볼 수 있다.
그래서 이런 타입의 join을 mutating join이라고 부른다.
이 케이스는, R의 base subsetting을 이용해서도 똑같이 할 수 있긴하다.
flights2 %>%
select(-origin, -dest) %>%
mutate(name = airlines$name[match(carrier, airlines$carrier)])
## # A tibble: 336,776 x 7
## year month day hour tailnum carrier name
## <int> <int> <int> <dbl> <chr> <chr> <chr>
## 1 2013 1 1 5 N14228 UA United Air Lines Inc.
## 2 2013 1 1 5 N24211 UA United Air Lines Inc.
## 3 2013 1 1 5 N619AA AA American Airlines Inc.
## 4 2013 1 1 5 N804JB B6 JetBlue Airways
## 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
## 6 2013 1 1 5 N39463 UA United Air Lines Inc.
## 7 2013 1 1 6 N516JB B6 JetBlue Airways
## 8 2013 1 1 6 N829AS EV ExpressJet Airlines Inc.
## 9 2013 1 1 6 N593JB B6 JetBlue Airways
## 10 2013 1 1 6 N3ALAA AA American Airlines Inc.
## # ... with 336,766 more rows
하지만 이렇게 하면, 여러 개 변수들로 매치를 시켜야할 때는, 일반화하기가 힘들다.
그리고 전반적인 의도를 이해하기 위해선 잘 읽어봐야한다.
그러니깐 그냥 dplyr를 쓰자.
이 다음의 section들은, mutating join이 어떻게 작동하는지 디테일하게 설명해준다.
joins의 시각적 표현을 통해서 하나씩 배워보자. 4개의 mutating join들.
the inner join 그리고 3개의 outer joins.
리얼 데이터들로 작업할 때는, keys가 항상 unique한 관측치를 identify하는 건 아니기 때문에, 만약에 unique match가 없을 때는 어떻게 해야할지에 대해서도 다룬다.
마지막으로, 주어진 join에 대해, dplyr에게 어떤 변수가 key인지 전달하는 방법에 대해 배울 것.
13.4.1 Understanding joins
joins가 어떻게 작동하는지 배우는데 도움을 주기위해, 다음과 같은 시각적 representation을 주겠다. 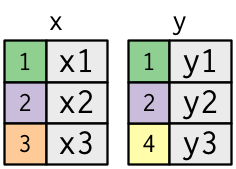
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
색이 있는 칼럼이 "key" 변수를 represent한다.
이 값으로 테이블 간에 행을 매치시키는 것임. used to match the rows between the tables.
회색 칼럼은 "key"값 옆에 따라나오는 "value" 칼럼이다.
이 예제에서는 하나만의 key 변수가 나오지만, 여러 개의 key 값들과 여러 개의 값들에 대해서도 일반화 가능하다.
join이라는 건 x의 각 행을, y의 몇 개의 행이 되든 상관없이 연결을 하는 것이다.
아래의 다이어그램은 가능한 매치를, 선들의 교차intersection으로 보였다. 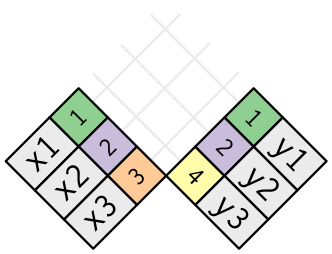
(x의 key 칼럼이랑 value 칼럼이랑 자리가 바뀐 걸 볼 수 있는데, 그냥 joins 매치는 key에 기반하고 있다는 걸 강조하기 위해서다. 별 거 아니다.)
실제로 join이 되는 것은, 점으로 표시된다.
점의 개수 = 매치의 개수 = output의 행 개수
13.4.2 Inner join
가장 단순한 타입의 join은 inner join이다.
key값이 같은 관측치들을 매치시키는 것.
An inner join / matches pairs of observations / whenever their keys are equal. 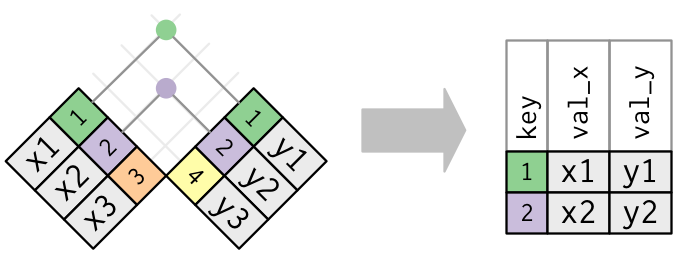
(정확하게 말하자면, keys가 equality 연산자operator를 사용해 매치하기 때문에, inner equijoin이라고 부른다. 그런데 대부분의 join이 equijoin이라 그냥 간단하게 inner join이라고 부름)
inner join의 output은, 새로운 데이터 프레임.
key값, x값, y값이 칼럼으로 있는.
어떤 변수가 key인지는, by를 사용해서 dplyr에 알려줄 수 있다.
x %>%
inner_join(y, by = "key")
## # A tibble: 2 x 3
## key val_x val_y
## <dbl> <chr> <chr>
## 1 1 x1 y1
## 2 2 x2 y2
inner join의 가장 중요한 특징으로는, 매치되지 않은 행들은 결과에 포함되지 않는다는 것이다.
이 말인즉슨, 관측치를 잃기가 너무 쉬워서, inner join은 data analysis에 일반적으로 적합하지 않다.
13.4.3 Outer joins
inner join은, 두 테이블 모두에 등장하는 관측치만을 keep했다.
outer join은 둘 중 하나의 테이블에만 존재해도, 관측치를 keep한다.
3가지 타입의 outer joins가 있다.
- left join은,
x에 있는 관측치들을 모두 keep. - right join은,
y에 있는 관측치들을 모두 keep. - full join은,
x와y에 있는 모든 관측치들을 keep.
이 join들은, 각 테이블에 "가상의" 관측치들을 추가함으로써 작동하는 것.
key값에 맞는 관측치가 없다면, NA로 채워서 만든다. 무슨 말인지 그림을 보면 쉽다. 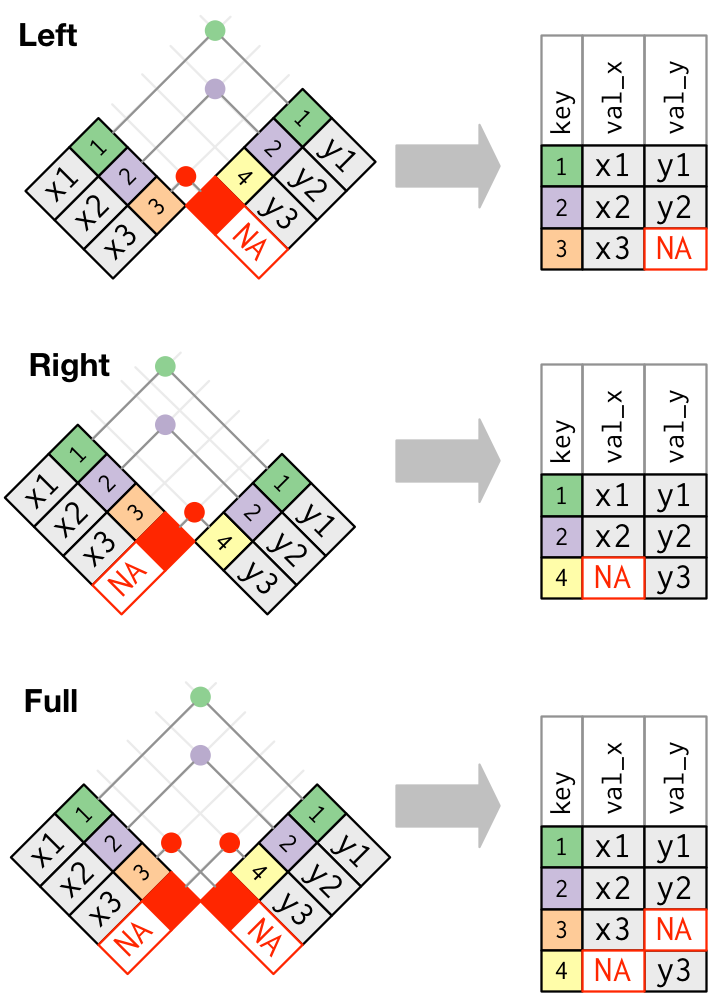
가장 흔하게 이용되는 join은, left join이다.
기존의 테이블에다가, 추가적인 데이터를 추가하고자 할 때 쓰는 것이다.
매치가 없더라도, 기존의 관측치들은 그대로 유지한다.
left join이 디폴트가 되야 한다. 다른 걸 써야하는게 아니라면 이걸 써라.
벤 다이어그램을 통해서도 이 join들을 표현할 수 있는데,
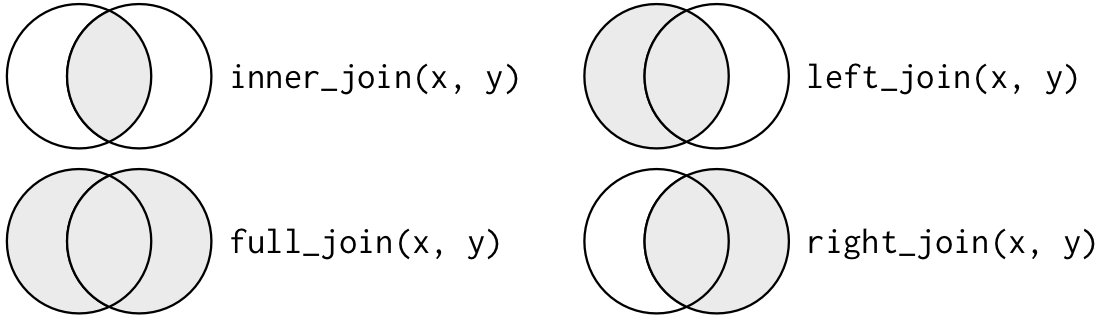
그런데 훌륭한 표현representation은 아니다.
어떤 테이블의 관측치들을 유지시켜주는지는 기억을 되살려줄수는 있어도, 큰 한계가 있다.
왜냐하면 벤 다이어그램은 keys가 관측치를 unique하게 identify하지 못할 때, 어떤 일이 일어나는지 보여주지 못하기 때문.
앞으로 살펴볼 그림들은, 그런 경우에 있어서 어떻게 하는지 표현해줌.
13.4.4 Duplicate Keys
이 때까지 모든 다이어그램들은, keys가 unique하다고 가정했다. 하지만 항상 그런 것은 아니다.
이 섹션에서는, keys가 unique하지 않을 때는 어떻게 하는지에 대해 설명한다.
2가지의 가능성이 있다.
- 하나의 테이블만 중복된 keys를 가지고 있을 때
이게 전형적인 일대다one-to-many 관계다.
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
1, "x4"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2"
)
left_join(x, y, by = "key")
## # A tibble: 4 x 3
## key val_x val_y
## <dbl> <chr> <chr>
## 1 1 x1 y1
## 2 2 x2 y2
## 3 2 x3 y2
## 4 1 x4 y1
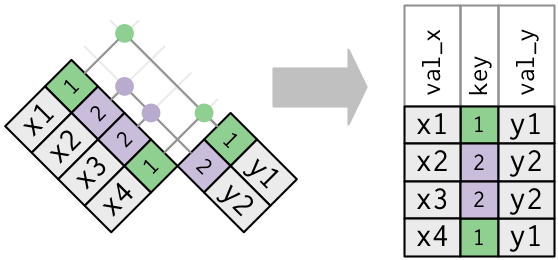
이 다이어그램을 보면, y에서는 primary key인게, x에서는 foreign key라는 걸 볼 수 있다.
- 두 테이블 모두 중복된 keys를 가지고 있을 때
이건 보통 에러다.
왜냐하면 key값이 어떠한 테이블에서도 관측치를 unique하게 identify하지 못하고 있으니깐.
그래서 이 중복된 key들을 가지고 join을 했을 때에는, 모든 가능한 combinations들을 갖게 된다.
이걸 Cartesian product라고 부른다.
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
3, "x4"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
2, "y3",
3, "y4"
)
left_join(x, y, by = "key")
## # A tibble: 6 x 3
## key val_x val_y
## <dbl> <chr> <chr>
## 1 1 x1 y1
## 2 2 x2 y2
## 3 2 x2 y3
## 4 2 x3 y2
## 5 2 x3 y3
## 6 3 x4 y4
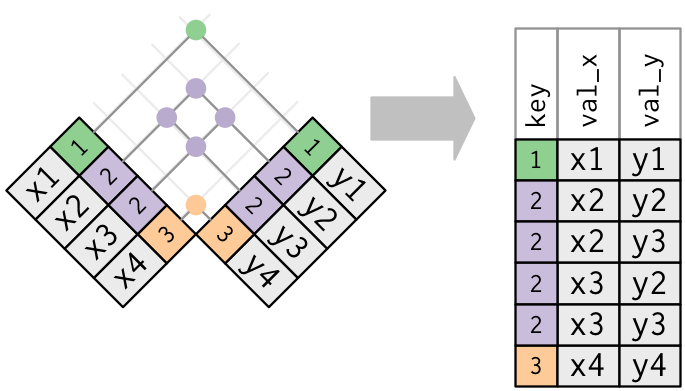
13.4.5 Defining the key columns
이 때까지, 한 쌍의 테이블들은 하나의 변수로 join이 되었다.
그리고 두 테이블 다 그 변수를 같은 name으로 갖고 있었다.
이걸 그냥 by = "key"라는 constraint로 encode했었고.
하지만 by에 다른 값들을 넣어서 두 테이블을 연결하는 걸 해보자.
- 디폴트는,
by = NULL이다. 양 쪽에 나오는 모든 변수들을 다 씀.
그래서 natural join이라고 부른다.
예를 들어서,flights2와weather두 테이블에는 5개의 공통 변수들이 존재한다.
year,month,day,hour,origin
flights2 %>%
left_join(weather)
## Joining, by = c("year", "month", "day", "hour", "origin")
## # A tibble: 336,776 x 18
## year month day hour origin dest tailnum carrier temp dewp humid
## <dbl> <dbl> <int> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 2013 1 1 5 EWR IAH N14228 UA 39.0 28.0 64.4
## 2 2013 1 1 5 LGA IAH N24211 UA 39.9 25.0 54.8
## 3 2013 1 1 5 JFK MIA N619AA AA 39.0 27.0 61.6
## 4 2013 1 1 5 JFK BQN N804JB B6 39.0 27.0 61.6
## 5 2013 1 1 6 LGA ATL N668DN DL 39.9 25.0 54.8
## 6 2013 1 1 5 EWR ORD N39463 UA 39.0 28.0 64.4
## 7 2013 1 1 6 EWR FLL N516JB B6 37.9 28.0 67.2
## 8 2013 1 1 6 LGA IAD N829AS EV 39.9 25.0 54.8
## 9 2013 1 1 6 JFK MCO N593JB B6 37.9 27.0 64.3
## 10 2013 1 1 6 LGA ORD N3ALAA AA 39.9 25.0 54.8
## # ... with 336,766 more rows, and 7 more variables: wind_dir <dbl>,
## # wind_speed <dbl>, wind_gust <dbl>, precip <dbl>, pressure <dbl>,
## # visib <dbl>, time_hour <dttm>
by에 캐릭터 벡터를 넣을 수도 있다.by = "x"이렇게.
nautral join과 비슷하다고 생각할 수 있지만, 이건 공통 변수의 일부만을 사용하는 것이다.
예를 들어,flights와planes는,year와tailnum이라는 공통 변수를 갖고 있다.
그런데,planes에서year은 비행기제조년도이고,flights에서year은 운항년도이다.
그래서 tailnum이라는 변수만 쓰고싶다.
그럼,
flights2 %>%
left_join(planes, by = "tailnum")
## # A tibble: 336,776 x 16
## year.x month day hour origin dest tailnum carrier year.y type
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <int> <chr>
## 1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixe~
## 2 2013 1 1 5 LGA IAH N24211 UA 1998 Fixe~
## 3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixe~
## 4 2013 1 1 5 JFK BQN N804JB B6 2012 Fixe~
## 5 2013 1 1 6 LGA ATL N668DN DL 1991 Fixe~
## 6 2013 1 1 5 EWR ORD N39463 UA 2012 Fixe~
## 7 2013 1 1 6 EWR FLL N516JB B6 2000 Fixe~
## 8 2013 1 1 6 LGA IAD N829AS EV 1998 Fixe~
## 9 2013 1 1 6 JFK MCO N593JB B6 2004 Fixe~
## 10 2013 1 1 6 LGA ORD N3ALAA AA NA <NA>
## # ... with 336,766 more rows, and 6 more variables: manufacturer <chr>,
## # model <chr>, engines <int>, seats <int>, speed <int>, engine <chr>
year 변수에 접미사suffix가 붙은 걸 인지하자.
by에 named vector를 넣어주는 거다.by = c("a" = "b")
이러면x테이블의a변수를y테이블의b변수랑 매치시켜준다.
그리고 변수 이름은x테이블의a를 쓰고. 예를 들어보자.
flights2 자료에는 origin과 dest가 있다.
여기에다가 airports의 faa라는 변수에 맞춰서 자료를 덧붙이고 싶다고 치자.
flights2 %>%
left_join(airports, c("dest" = "faa"))
## # A tibble: 336,776 x 15
## year month day hour origin dest tailnum carrier name lat lon
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2013 1 1 5 EWR IAH N14228 UA Geor~ 30.0 -95.3
## 2 2013 1 1 5 LGA IAH N24211 UA Geor~ 30.0 -95.3
## 3 2013 1 1 5 JFK MIA N619AA AA Miam~ 25.8 -80.3
## 4 2013 1 1 5 JFK BQN N804JB B6 <NA> NA NA
## 5 2013 1 1 6 LGA ATL N668DN DL Hart~ 33.6 -84.4
## 6 2013 1 1 5 EWR ORD N39463 UA Chic~ 42.0 -87.9
## 7 2013 1 1 6 EWR FLL N516JB B6 Fort~ 26.1 -80.2
## 8 2013 1 1 6 LGA IAD N829AS EV Wash~ 38.9 -77.5
## 9 2013 1 1 6 JFK MCO N593JB B6 Orla~ 28.4 -81.3
## 10 2013 1 1 6 LGA ORD N3ALAA AA Chic~ 42.0 -87.9
## # ... with 336,766 more rows, and 4 more variables: alt <int>, tz <dbl>,
## # dst <chr>, tzone <chr>
flights2 %>%
left_join(airports, c("origin" = "faa"))
## # A tibble: 336,776 x 15
## year month day hour origin dest tailnum carrier name lat lon
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2013 1 1 5 EWR IAH N14228 UA Newa~ 40.7 -74.2
## 2 2013 1 1 5 LGA IAH N24211 UA La G~ 40.8 -73.9
## 3 2013 1 1 5 JFK MIA N619AA AA John~ 40.6 -73.8
## 4 2013 1 1 5 JFK BQN N804JB B6 John~ 40.6 -73.8
## 5 2013 1 1 6 LGA ATL N668DN DL La G~ 40.8 -73.9
## 6 2013 1 1 5 EWR ORD N39463 UA Newa~ 40.7 -74.2
## 7 2013 1 1 6 EWR FLL N516JB B6 Newa~ 40.7 -74.2
## 8 2013 1 1 6 LGA IAD N829AS EV La G~ 40.8 -73.9
## 9 2013 1 1 6 JFK MCO N593JB B6 John~ 40.6 -73.8
## 10 2013 1 1 6 LGA ORD N3ALAA AA La G~ 40.8 -73.9
## # ... with 336,766 more rows, and 4 more variables: alt <int>, tz <dbl>,
## # dst <chr>, tzone <chr>
13.4.6 Exercises
13.4.7 Other implementations
base::merge()를 통해서 4가지의 mutating joins를 다 할 수 있다.
| dplyr | base::merge() |
|---|---|
inner_join(x, y) |
merge(x, y) |
left_join(x, y) |
merge(x, y, all.x = TRUE) |
right_join(x, y) |
merge(x, y, all.y = TRUE) |
full_join(x, y) |
merge(x, y, all.x = TRUE, all.y = TRUE) |
근데 dplyr의 verbs가 더 깔끔하게 코드 의도를 전달한다.
SQL이 dplyr 고안convention의 영감이었기 때문에, 그대로 해석하면 된다.
| dplyr | SQL |
|---|---|
inner_join(x, y, by = "z") |
SELECT * FROM x INNER JOIN y USING (z) |
left_join(x, y, by = "z") |
SELECT * FROM x LEFT JOIN y USING (z) |
right_join(x, y, by = "z") |
SELECT * FROM x RIGHT JOIN y USING (z) |
full_join(x, y, by = "z") |
SELECT * FROM x FULL JOIN y USING (z) |
여기 SQL에서 "INNER"이랑 "OUTER"은 생략할 수 있다.
테이블 간의 다른 변수들을 joining하는데 있어, dplyr이랑 SQL은 조금 다른 문법syntax을 쓴다.
inner_join(x, y, by = c("a" = "b"))를 SQL로 써보면, SELECT * FROM x INNER JOIN y ON x.a = y.b이다.
이렇게 문법을 보면 알 수 있듯, SQL은 non-equijoins라고 불리는, dplyr보다 더 넓은 범위의 join types를 지원한다.
13.5 Filtering joins
filtering joins는, mutating joins와 마찬가지 방법으로 관측치obs를 match한다.
그런데 차이점이 있다면, 이제는 관측치에 영향을 주는 것. 변수가 아니라.
affect the observations, not the variables.
2가지 타입들이 있다.
-
semi_join()은y와 매치가 되는 모든x들을 keep함. -
anti_join()은y와 매치가 되는 모든x들을 drop함.
semi_join은, 필터링한 summary tables를 원래의 테이블에 매칭할 때 매우 유용하다.
Semi_joins are useful for matching filtered summary tables back to the original rows.
또 말이 어렵다. 예를 보면 그냥 쉽게 이해된다.
flights에서 10개의 가장 유명한 목적지들을 찾았다고 치자.
top_dest <- flights %>%
count(dest, sort = TRUE) %>%
head(10)
top_dest
## # A tibble: 10 x 2
## dest n
## <chr> <int>
## 1 ORD 17283
## 2 ATL 17215
## 3 LAX 16174
## 4 BOS 15508
## 5 MCO 14082
## 6 CLT 14064
## 7 SFO 13331
## 8 FLL 12055
## 9 MIA 11728
## 10 DCA 9705
그리고 이 목적지들에 갔던 flights들을 다 찾고 싶다고 치자.
그럼 다음과 같이 필터를 만들어볼 수 있다.
flights %>%
filter(dest %in% top_dest$dest)
## # A tibble: 141,145 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 542 540 2 923
## 2 2013 1 1 554 600 -6 812
## 3 2013 1 1 554 558 -4 740
## 4 2013 1 1 555 600 -5 913
## 5 2013 1 1 557 600 -3 838
## 6 2013 1 1 558 600 -2 753
## 7 2013 1 1 558 600 -2 924
## 8 2013 1 1 558 600 -2 923
## 9 2013 1 1 559 559 0 702
## 10 2013 1 1 600 600 0 851
## # ... with 141,135 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>
하지만, 변수가 많아지면 이러한 접근법을 사용할 수가 없다.
예를 들어, 평균 딜레이가 많았던 10일을 찾았다치자.
그럼 이 자료로 flights에 어떻게 필터문filter statement를 작성할건지?
year, month, day를 다 이용해서 어떻게?
이럴 땐 그냥 대신에 semi_join()을 사용하면 된다.
mutating join과 같이 2개의 테이블을 연결하지만, 새로운 칼럼을 추가하는게 아니고,
y와 매치가 되는 x만 keep한다.
flights %>%
semi_join(top_dest)
## Joining, by = "dest"
## # A tibble: 141,145 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 542 540 2 923
## 2 2013 1 1 554 600 -6 812
## 3 2013 1 1 554 558 -4 740
## 4 2013 1 1 555 600 -5 913
## 5 2013 1 1 557 600 -3 838
## 6 2013 1 1 558 600 -2 753
## 7 2013 1 1 558 600 -2 924
## 8 2013 1 1 558 600 -2 923
## 9 2013 1 1 559 559 0 702
## 10 2013 1 1 600 600 0 851
## # ... with 141,135 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>
그림으로 표현해보면, semi-join은 다음과 같이 생겼다. 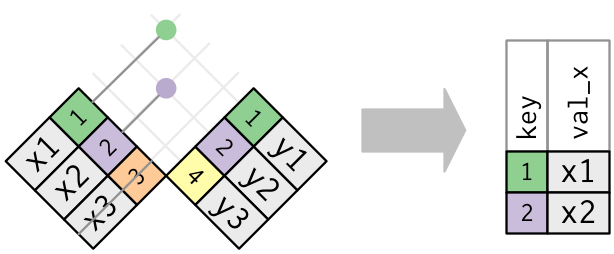
매치가 존재하는 것만이 중요하다. 어떤 관측치obs가 매치되었는지는 중요치 않다.
그래서, mutating joins와는 다르게, filtering join은 절대 rows를 중복하지 않는다. 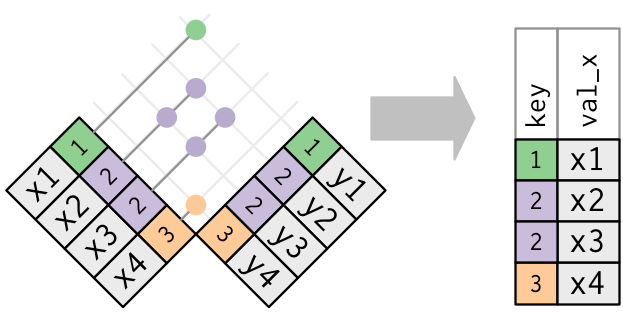
semi-join의 반대는 anti-join이다. anti-join은 매치가 없는 rows만을 남긴다. 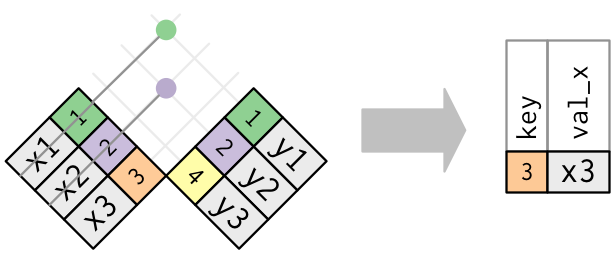
anti-join은 join mismatch를 진단하는데 유용하다.
예를 들어서, flights와 planes를 연결하는데 있어, planes에는 없는 비행기로 운항이 된 적이 있는지를 알아보고 싶다치자.
flights %>%
anti_join(planes, by = "tailnum") %>%
count(tailnum, sort = TRUE)
## # A tibble: 722 x 2
## tailnum n
## <chr> <int>
## 1 <NA> 2512
## 2 N725MQ 575
## 3 N722MQ 513
## 4 N723MQ 507
## 5 N713MQ 483
## 6 N735MQ 396
## 7 N0EGMQ 371
## 8 N534MQ 364
## 9 N542MQ 363
## 10 N531MQ 349
## # ... with 712 more rows
꽤나 많네 생각보다. 너무 많아서 그걸 tailnum별로 내림차순 정렬까지 해봤다.
이 anti_join()은 상당히 유용한게, cross validation을 할 때, 데이터의 80%는 train으로 쓰고, 나머지 20%는 test로 쓸 때가 있다. 이걸 되게 쉽게 해준다.
set.seed(1234)
train <- data %>%
sample_frac(0.8) # 80%를 train으로
test <- data %>%
anti_join(train) # 나머지 20%를 test로
13.5.1 Exercises
13.6 Join problems
이 chapter에서 다루는 데이터는, clean up이 다 되어있는 데이터라서 별 문제가 없다.
너의 데이터는 그렇지 않을 것이기에, 너가 join을 스무스하게 하기 위해 필요한 것들을 알려주겠다.
- 각 테이블에서 primary key를 identifying하는 것으로 시작을 해라.
이건 데이터에 대한 이해가 필요하다.
이것저것해보면서 끼워맞추지말고, 어떤 의미를 갖는지 이해하면서 찾아라.
그딴 식으로 찾으면 찾아도 별로 의미가 없을 것이다.
예를 들어,airports에서alt,lon가지고 unique하게 identify할 수 있지만, 좋은게 아니다.
airports %>%
count(alt, lon) %>%
filter(n > 1)
## # A tibble: 0 x 3
## # ... with 3 variables: alt <int>, lon <dbl>, n <int>
-
primary key의 어떠한 변수도 missing이 아니라는 걸 체크해라.
만약에 missing이 있다면, 이건 관측치를 identify할 수 없는거다. -
한 테이블에서 primary key인게 다른 테이블에서 foreign key와 match된다는 걸 확인해라.
anti_join()을 이용해서 하는게 제일 좋은 방법이다.
무슨 소리인지 잘 이해가 안 되어서 없는 예를 만들어보겠다.
위에서 봤듯이,flights에 나와 있는 비행기가,planes에 다 있는 건 아니다.
그러니깐,planes에 없는 비행기로도 운항이 이루어진 적이 있다.
배운 용어로 해보면,flights의tailnum은,planes의 primary key가 되는 foreign key다.
이걸 확인해볼 때anti_join()을 쓸 수 있다는 것이다.
planes %>%
anti_join(flights, by = "tailnum")
## # A tibble: 0 x 9
## # ... with 9 variables: tailnum <chr>, year <int>, type <chr>,
## # manufacturer <chr>, model <chr>, engines <int>, seats <int>,
## # speed <int>, engine <chr>
이러면 아무것도 안 나오므로,
flights의 tailnum은, planes의 primary key가 되는 foreign key라는 것을 확인할 수 있다.
또한, join 전후의 rows를 체크하는 것으로는, join이 잘 되었는지 아닌지를 판단할 수 없다.
왜냐하면 양 테이블에 중복된 keys가 있을 때 inner join을 했다가,
drop된 rows가 duplicated rows랑 기가 막히게 일치해버릴 수가 있기 때문.
13.7 Set operations
mutating joins, filtering joins에 대해 배웠고, 마지막으로 배워야할 verb는, set operations다.
이건 쉽다.
자주 이용하지는 않지만, single complex filter를 simpler pieces로 쪼갤 때 유용.
관측치의 모든 값들을 다 비교한다.
x랑 y가 같은 변수를 가져야하며, 관측치를 set과 같이 다룬다.
intersect(x, y):x와y둘 다에서 나타나는 관측지만을 반환union(x, y):x와y둘 중 하나에서만 나타나도 모든 관측지를 반환setdiff(x, y):x에는 있지만y에는 없는 관측지를 반환
그럼 다음과 같은 간단한 데이터에 대해서,
df1 <- tribble(
~x, ~y,
1, 1,
2, 1,
)
df2 <- tribble(
~x, ~y,
1, 1,
1, 2
)
총 4가지를 해볼 수 있겠다.
intersect(df1, df2)
## # A tibble: 1 x 2
## x y
## <dbl> <dbl>
## 1 1 1
union(df1, df2)
## # A tibble: 3 x 2
## x y
## <dbl> <dbl>
## 1 1 2
## 2 2 1
## 3 1 1
setdiff(df1, df2) # df1에는 있지만 df2에는 없는 것
## # A tibble: 1 x 2
## x y
## <dbl> <dbl>
## 1 2 1
setdiff(df2, df1) # df2에는 있지만 df1에는 없는 것
## # A tibble: 1 x 2
## x y
## <dbl> <dbl>
## 1 1 2